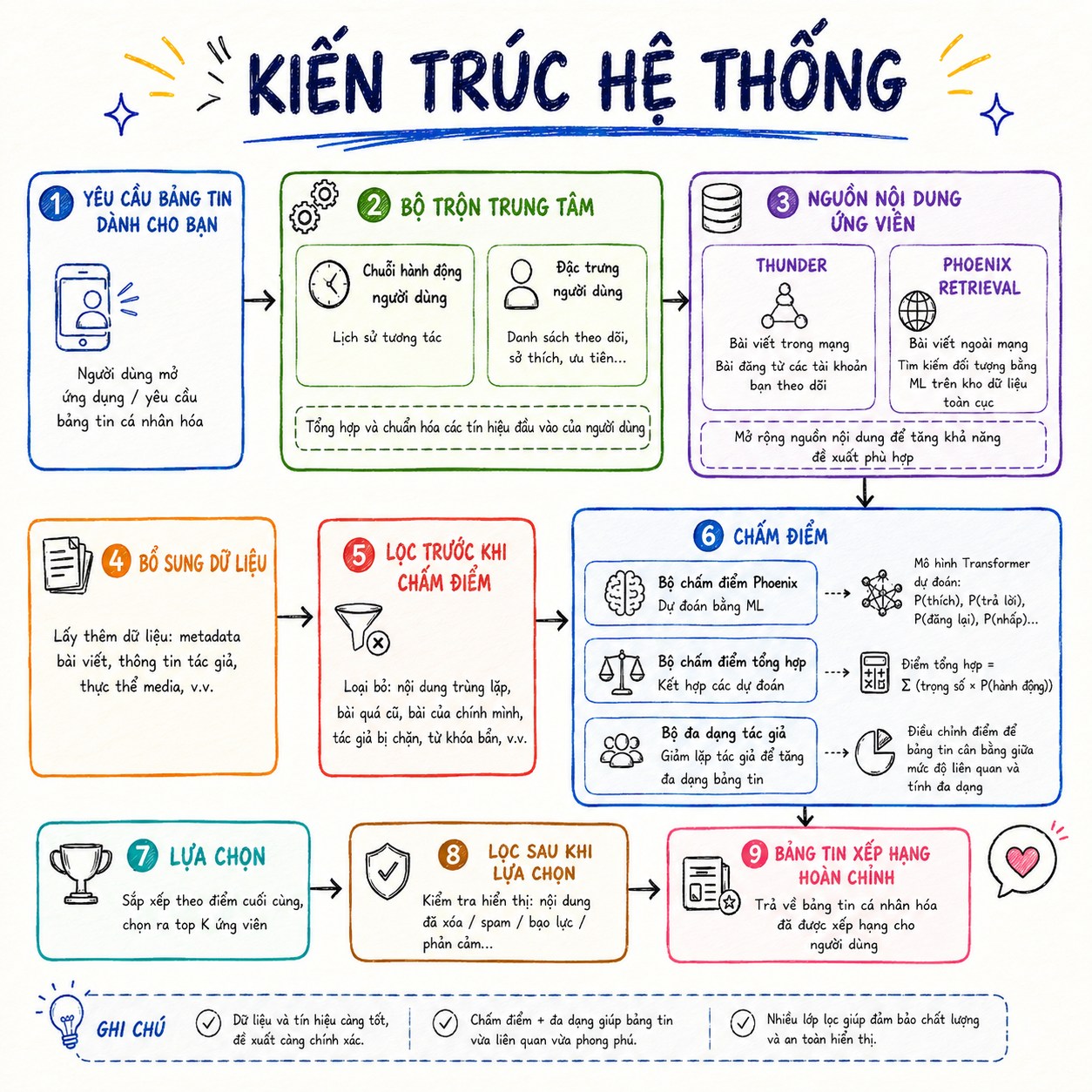
xAI/X vừa công khai repo x-algorithm trên GitHub – phần lõi của hệ thống đề xuất nội dung cho tab “For You” trên X. Đây là một phần kiến trúc đứng sau việc vì sao mỗi người nhìn thấy một dòng nội dung khác nhau khi mở X. Repo hiện mô tả hệ thống recommendation kết hợp nội dung từ những tài khoản người dùng theo dõi và nội dung ngoài mạng lưới được tìm bằng mô hình học máy, sau đó xếp hạng bằng một mô hình transformer dựa trên Grok/Phoenix.
Feed không còn đơn giản là hiển thị bài mới nhất, bài nhiều like nhất, hay bài từ người mình follow. Feed giờ là một hệ thống AI nhiều tầng, liên tục hiểu hành vi, dự đoán phản ứng và tối ưu từng vị trí hiển thị.
1. “For You” không chỉ lấy bài từ người bạn follow
Theo mô tả trong repo, hệ thống lấy nội dung từ hai nguồn chính:
Một là In-Network, tức bài viết từ những tài khoản bạn đang theo dõi, thông qua thành phần Thunder.
Hai là Out-of-Network, tức những bài viết ngoài vòng follow của bạn, được Phoenix Retrieval tìm ra từ kho nội dung lớn dựa trên tương đồng và tín hiệu học máy.
Điều này giải thích vì sao trên X, Facebook, TikTok hay YouTube, chúng ta ngày càng thấy nhiều nội dung từ những người mình chưa từng biết. Nền tảng không chỉ phục vụ “mạng xã hội” theo nghĩa kết nối bạn bè, mà đang vận hành như một cỗ máy khám phá nội dung cá nhân hóa.
Bạn không chỉ đang xem những gì mình chọn theo dõi. Bạn đang xem những gì hệ thống dự đoán rằng bạn có khả năng dừng lại, tương tác, phản hồi, chia sẻ hoặc tiếp tục xem.
2. Thuật toán hiện đại không còn chỉ dựa vào vài chỉ số thủ công
Một điểm rất đáng chú ý trong repo là hệ thống tuyên bố đã loại bỏ hầu hết các đặc trưng thủ công và heuristic truyền thống. Thay vào đó, mô hình transformer dựa trên Grok học trực tiếp từ chuỗi hành vi của người dùng: bạn like gì, reply gì, repost gì, click gì, xem gì, bỏ qua gì.
Đây là sự thay đổi lớn.
Trước đây, nhiều hệ thống recommendation thường dựa trên các luật tương đối rõ ràng: bài mới, nhiều tương tác, có từ khóa phù hợp, tác giả uy tín, cùng chủ đề, cùng nhóm người dùng… Nhưng với hệ thống hiện đại, mô hình không chỉ hỏi: “Bài này có nhiều like không?” mà hỏi: “Với lịch sử hành vi của người này, xác suất họ sẽ phản ứng với bài này theo từng cách là bao nhiêu?”
Tức là nền tảng không chỉ đo nội dung. Nó đo khả năng tạo hành vi.
3. Mỗi bài viết được chấm điểm theo nhiều loại hành động
Phoenix không chỉ dự đoán một điểm “phù hợp” chung chung. Nó dự đoán xác suất cho nhiều hành động khác nhau: like, reply, repost, quote, click, xem video, mở ảnh, chia sẻ, follow tác giả, thậm chí cả các hành động tiêu cực như không quan tâm, block, mute, report. Sau đó hệ thống kết hợp các xác suất này bằng trọng số để tạo ra điểm cuối cùng.
Điều này rất quan trọng với người làm nội dung.
Vì trong mắt thuật toán, một bài viết không đơn giản là “hay” hay “dở”. Nó là một tập hợp xác suất:
- Bài này có khiến người xem dừng lại không?
- Có khiến họ bấm vào không?
- Có khiến họ bình luận không?
- Có khiến họ chia sẻ không?
- Có khiến họ khó chịu và block không?
- Có khiến họ xem video lâu hơn không?
- Có khiến họ follow tác giả không?
Nói cách khác, thuật toán không chỉ đánh giá nội dung theo giá trị nội dung, mà theo hệ quả hành vi mà nội dung có khả năng tạo ra.
4. Feed là một pipeline, không phải một thuật toán đơn lẻ
Repo cho thấy hệ thống For You gồm nhiều bước: lấy ngữ cảnh người dùng, tìm ứng viên nội dung, bổ sung dữ liệu cho từng ứng viên, lọc bài không phù hợp, chấm điểm, chọn top nội dung và tiếp tục lọc sau khi chọn.
Một bài viết trước khi xuất hiện trên màn hình của bạn phải đi qua nhiều lớp:
- Nó có bị trùng không?
- Có quá cũ không?
- Có đến từ tài khoản bạn đã block hoặc mute không?
- Bạn đã từng thấy bài này chưa?
- Nó có chứa keyword bạn đã mute không?
- Nó có vi phạm các lớp kiểm duyệt như spam, bạo lực, nội dung nhạy cảm không?
- Tác giả đó có xuất hiện quá nhiều trong feed của bạn không?
Điều này cho thấy “thuật toán” thực chất là một hệ điều hành phân phối sự chú ý. Nó không chỉ ranking, mà còn retrieval, filtering, hydration, scoring, diversity control, policy enforcement và logging.
5. Vì sao người làm nội dung cần hiểu điều này?
Vì cuộc chơi nội dung không còn là “đăng nhiều hơn” hay “viết giật tít hơn”.
Cuộc chơi mới là: thiết kế nội dung tạo ra tín hiệu hành vi chất lượng.
Một bài viết tốt trên nền tảng AI recommendation cần có ít nhất 5 lớp:
- Thứ nhất, mở đầu đủ mạnh để người đọc dừng lại.
- Thứ hai, nội dung đủ rõ để hệ thống hiểu đúng chủ đề.
- Thứ ba, insight đủ sâu để người đọc muốn lưu, bình luận hoặc chia sẻ.
- Thứ tư, cấu trúc đủ mạch lạc để người đọc ở lại lâu hơn.
- Thứ năm, độ tin cậy đủ cao để không tạo tín hiệu tiêu cực như bỏ qua, report, mute, block.
Điều này đặc biệt quan trọng với doanh nghiệp, chuyên gia, nhà đào tạo và người xây thương hiệu cá nhân. Nếu chỉ chạy theo tương tác rẻ, nội dung có thể tạo spike ngắn hạn nhưng làm hỏng tín hiệu dài hạn. Ngược lại, nếu nội dung có chiều sâu nhưng quá khó đọc, thiếu điểm dừng, thiếu hook, thiếu cấu trúc, thuật toán cũng khó phân phối rộng.
6. Bài học cho doanh nghiệp: AI đang trở thành lớp điều phối mọi trải nghiệm số
Nhìn rộng hơn, repo này không chỉ là câu chuyện của X. Nó phản ánh xu hướng lớn hơn: mọi nền tảng số đang chuyển từ phần mềm tĩnh sang hệ thống AI điều phối động.
Trang chủ, newsfeed, email marketing, CRM, e-commerce, LMS, app học tập, nền tảng nội bộ doanh nghiệp… tất cả đều có thể được tái thiết kế theo logic:
- Hiểu người dùng
- Lấy ứng viên phù hợp
- Bổ sung dữ liệu ngữ cảnh
- Lọc theo rủi ro và chính sách
- Dự đoán hành vi
- Xếp hạng
- Cá nhân hóa trải nghiệm
- Học lại từ phản hồi
Đây chính là tư duy mà doanh nghiệp cần học. AI không chỉ là chatbot trả lời câu hỏi. AI đang trở thành lớp ra quyết định mềm nằm giữa dữ liệu, nội dung, quy trình và người dùng.
Người thắng không phải người “hack thuật toán”, mà là người hiểu hệ thống
Nhiều người vẫn hỏi: “Làm sao để thắng thuật toán?”
Nhưng câu hỏi đúng hơn là: “Làm sao tạo ra nội dung, sản phẩm và trải nghiệm đủ tốt để hệ thống có lý do phân phối mình nhiều hơn?”
Từ repo x-algorithm, có thể thấy một điều rất rõ: các nền tảng không còn vận hành bằng vài mẹo đơn giản. Chúng là những pipeline AI phức tạp, liên tục học từ hành vi người dùng, cân bằng giữa tương tác, an toàn, đa dạng, cá nhân hóa và mục tiêu kinh doanh.
Với cá nhân làm thương hiệu: hãy xây nội dung có chiều sâu, có cấu trúc, có tín hiệu hành vi tốt.
Với doanh nghiệp: hãy bắt đầu nghĩ về AI không chỉ như công cụ tạo nội dung, mà như một lớp kiến trúc để cá nhân hóa trải nghiệm khách hàng, tối ưu vận hành và ra quyết định theo dữ liệu.
Với người học AI: đây là một case study rất đáng đọc. Vì nó cho thấy recommendation system hiện đại không chỉ là machine learning, mà là sự kết hợp của dữ liệu, mô hình, hạ tầng, sản phẩm, chính sách và hành vi con người.
AI đang quyết định nội dung nào được nhìn thấy.
Và đó mới là thay đổi lớn nhất.